
Is AI quietly killing itself – and the Internet?
Lately, I’ve been deeply immersed in artificial intelligence research. This interest has been fueled by Elon Musk’s recent announcement of his new AI supercomputer, “Colossus.” Doubled, Colossus is billed as the world’s most powerful AI training system. Given its revolutionary nature, I plan to focus my upcoming posts on the fascinating field of artificial intelligence.
* I mentioned AI in a post in the ChatGPT section
Elon Musk’s AI supercomputer is here

I recently came across a particularly well-designed text on the subject, written in an interesting and slightly artistic style. I will share it here in its entirety.
Is there a comforting perspective?
Read below or You can follow this LINK for the original content.
Interest in artificial intelligence continues to surge, as Google searches over the past 12 months are at 92% of their all-time peak, but recent research suggests AI’s success could be its downfall. Amid the growth of AI content online, a group of researchers at Cambridge and Oxford universities set out to see what happens when generative AI tools query content produced by AI. What they found was alarming.

University of Oxford’s Dr. Ilia Shumailov and the team of researchers discovered that when generative AI software relies solely on content produced by genAI, the responses begin to degrade, according to the study published in Nature last month.
After the first two prompts, the answers steadily miss the mark, followed by a significant quality downgrade by the fifth attempt and a complete devolution to nonsensical pablum by the ninth consecutive query. The researchers dubbed this cyclical overdose on generative AI content model collapse—a steady decline in the learned responses of the AI that continually pollutes the training sets of repeating cycles until the output is a worthless distortion of reality
“It is surprising how fast model collapse kicks in and how elusive it can be. At first, it affects minority data—data that is badly represented. It then affects diversity of the outputs and the variance reduces. Sometimes, you observe small improvement for the majority data, that hides away the degradation in performance on minority data. Model collapse can have serious consequences,” Shumailov explains in an email exchange.
This matters because roughly 57% of all web-based text has been AI generated or translated through an AI algorithm, according to a separate study from a team of Amazon Web Services researchers published in June. If human-generated data on the internet is quickly being papered over with AI-generated content and the findings of Shumailov’s study are true, it’s possible that AI is killing itself—and the internet.
Researchers Found AI Fooling Itself
Here’s how the team confirmed model collapse was occurring. They began with a pre-trained AI-powered wiki that was then updated based on its own generated outputs going forward. As the tainted data contaminated the original training set of facts, the information steadily eroded to unintelligibility.
For instance, after the ninth query cycle, an excerpt from the study’s wiki article on 14th century English church steeples had comically morphed into a hodgepodge thesis regarding various colors of jack-tailed rabbits. ( me 😂 )
Another example cited in the Nature report to illustrate the point involved a theoretical example of an AI trained on dog varieties. Based on the study findings, lesser-known breeds would be excluded from the repeated data sets favoring more popular breeds like golden retrievers. The AI creates its own de facto “use it or lose it” screening method that removes less popular breeds from its data memory. But with enough cycles of only AI inputs, the AI is only capable of meaningless results, as depicted in Figure 1 below.
“In practice, imagine you wanted to build an AI model that generates pictures of animals. If before machine learning models you could simply find pictures of animals online and build a model from them, then today it gets more complex. Many pictures online are not real and include misconceptions introduced by other models,” Shumailov explains.
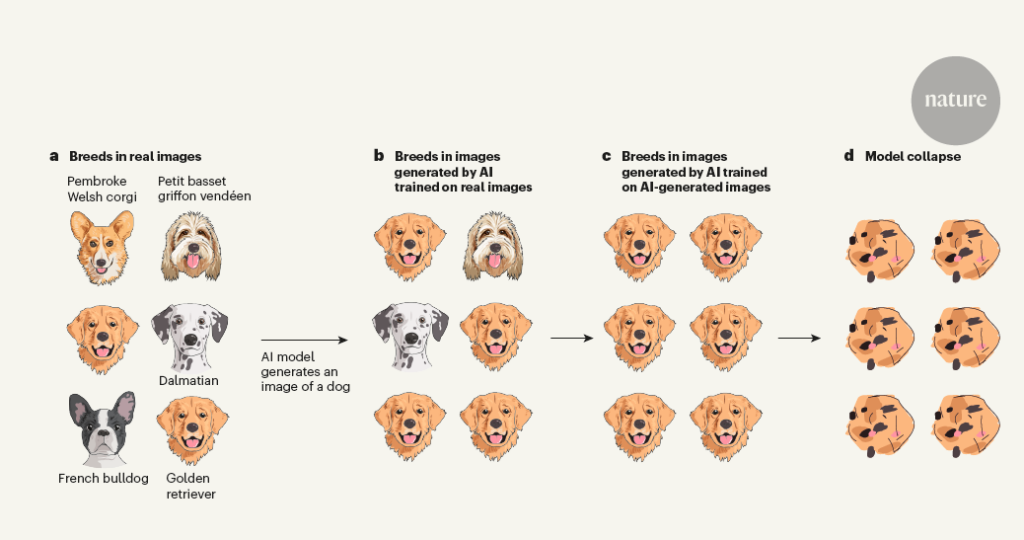
How Does Model Collapse Happen?
For some reason—and the researchers don’t fully know why—when AI feeds only on a steady diet of its own synthetic data, it loses touch with original threads of reality and tends to create its own best answer based on its own best recycled data points.
But something gets lost in that AI translation and factoid regurgitation.
The study concludes that the only way that artificial intelligence can achieve long-term sustainability is to ensure its access to the existing body of non-AI, human-produced content as well as providing for a continual stream of new human-generated content going forward.
Tide of AI-Generated Content Online is Rising Rapidly
However, nowadays you can’t seem to swing a lolcat meme over your head without hitting an AI-generated piece of content on the internet—and it might be worse than you think.
In fact, one AI expert and policy advisor has predicted that because of the exponential growth of artificial intelligence adoption, 90% of all internet content is likely to be AI-generated sometime in 2025.
Even if the percentage of AI-produced materials is not 90% by next year, it will still be a disproportionate percentage of the available training content for any future AI. That’s not a comforting prospect based on Shumailov’s findings and the lack of a clear solution to this problem, which is only going to grow with the popularity of generative AI.
Houston We Have A Problem—Make That Problems
No one knows what legal or regulatory guardrails may be enforced in coming months and years that could restrict access to the existing bolus or significant swaths of copyrighted human-sourced content.
Additionally, with so much of the internet’s current content generated using AI, with no way of realistically slowing that explosive trend, it’s going to be a challenge for developers of next-generation AI algorithms to avoid this situation completely as the ratio of original human content shrinks. Further complicating the matter, Shumailov says it’s becoming more challenging for human developers to filter out content created by large language model AI systems at scale, with no apparent solution in sight. “Not as of currently. There is an active academic discussion, and hopefully we will make progress on how to address model collapse while minimizing associated costs,” Shumailov states.
“One option is community-wide coordination to ensure that different parties involved in LLM creation and deployment share the information needed to resolve questions of provenance,” Shumailov adds. “Otherwise, it may become increasingly difficult to train newer versions of LLMs without access to data that were crawled from the Internet before the mass adoption of the technology or direct access to data generated by humans at scale.”
Shumailov says the most significant implication of model collapse is the corruption of previously unbiased training sets, which will now skew toward errors, mistakes, and unfairness. It would also amplify disinformation and hallucinations—best guesses AI makes absent real data—which have already come to light across several genAI platforms.
Given the steady march toward AI model collapse, everything online may have to be verified via an immutable system such as blockchain or some “Good Housekeeping” seal of approval equivalent to ensure trust.
Otherwise, the death of AI and the internet might actually mean the death of truth.
This article was first published on forbes.com the section Innovation and AI Innovation AI
Thank you Tor Constantino, MBA and Editors-picks


